Segment Factorized Full Song Generation on Symbolic Piano Music
This is my first music generation paper, presented at the NeurIPS 2025 AI for Music Workshop.
While reading prior work, I notice that full-song generation models need to achieve two challenging goals at once: maintaining global coherence while efficiently generating long sequences. To address this, there has been several approaches using techniques such as hierarchical generation or selective attention mechanisms.
Then I started wondering: why don’t humans seem to encounter this problem when writing music?
Think about how people naturally compose songs. A composer rarely writes a song strictly left to right while constantly keeping the entire piece in mind. Instead, they usually start with a theme and a rough song structure, decide where that theme appears, and then gradually fill in the rest. When working on a specific section, they only refer to the most relevant parts of the song, not the entire composition, which is partially autoregressive. Revisiting everything all the time would be unnecessary and inefficient.
We took inspiration from this human workflow: first decide the song’s structure and theme, then fill in the surrounding content. To use our model, the user provides a song structure, optionally with a seed segment. The model then generates the remaining segments by selectively attending to related parts of the song.
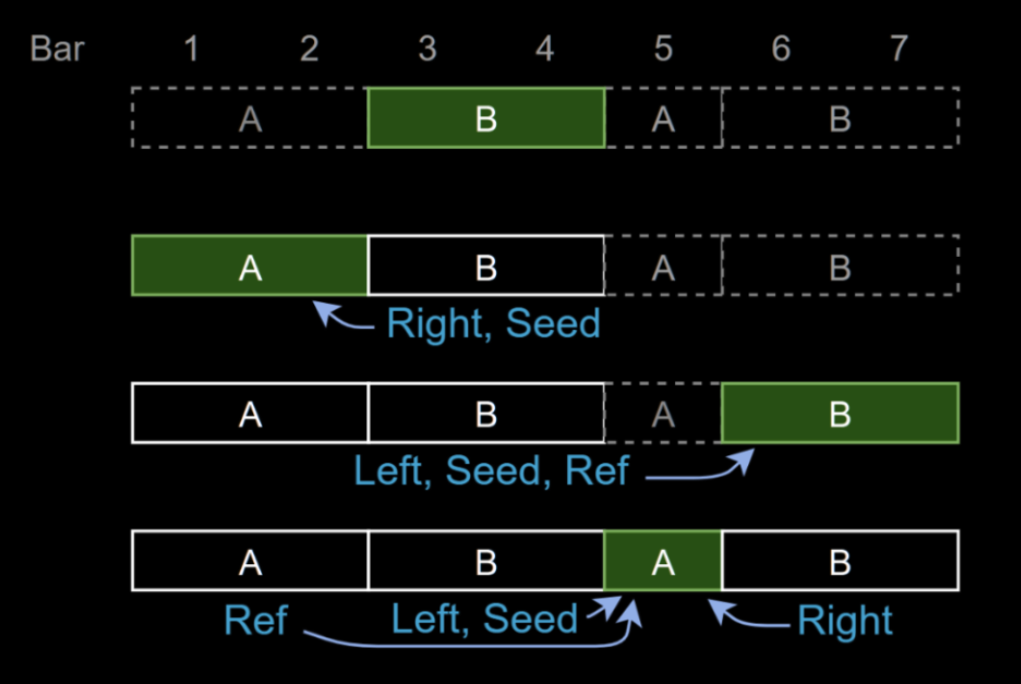
This design has a few nice properties. The model can generate music in real time (around 120 BPM on an RTX4090), and it doesn’t require strict chronological order, so it can better fit into the human user’s workflow, where ideas for different part of the song may emerge out of order.
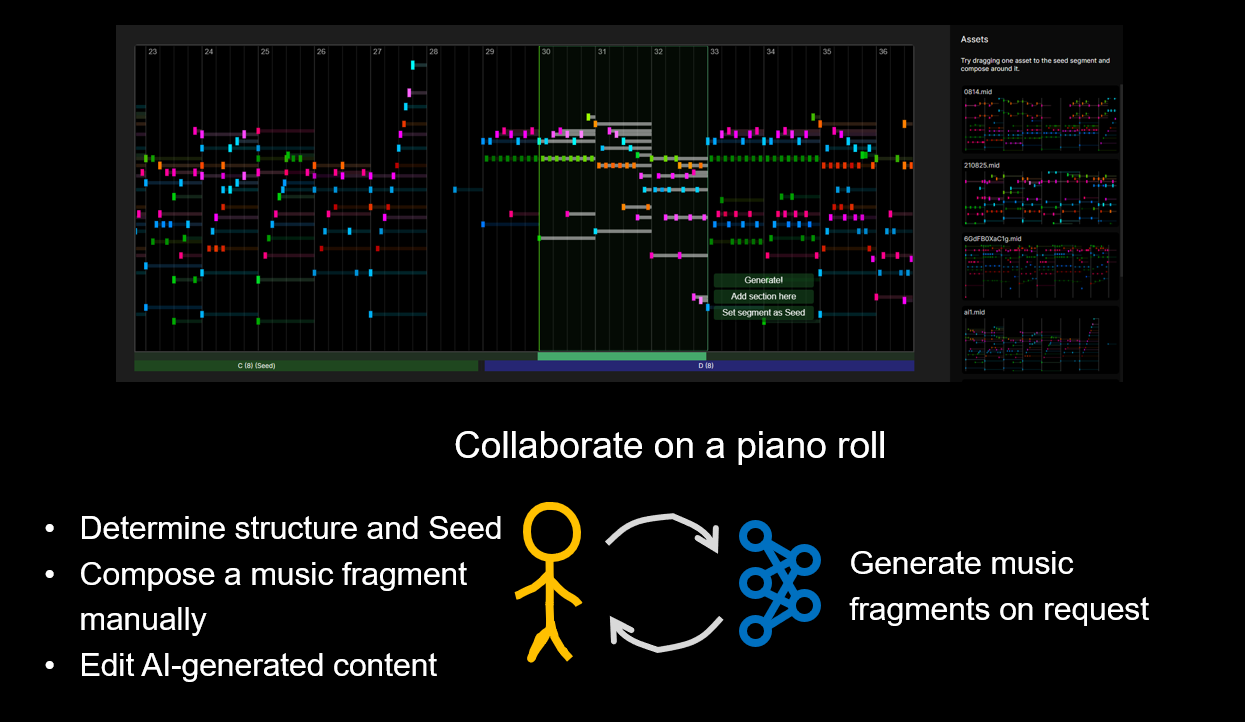
I always like my projects to be interactive, so I built an interface where users can iteratively co-create music with the model (demo around 0:40 in the video above).
Abstract:
We propose the Segmented Full-Song Model (SFS) for symbolic full-song generation. The model accepts a user-provided song structure and an optional short seed segment that anchors the main idea around which the song is developed. By factorizing a song into segments and generating each one through selective attention to related segments, the model achieves higher quality and efficiency compared to prior work. To demonstrate its suitability for human–AI interaction, we further wrap SFS into a web application that enables users to iteratively co-create music on a piano roll with customizable structures and flexible ordering.
Learn more at the paper and the project page.